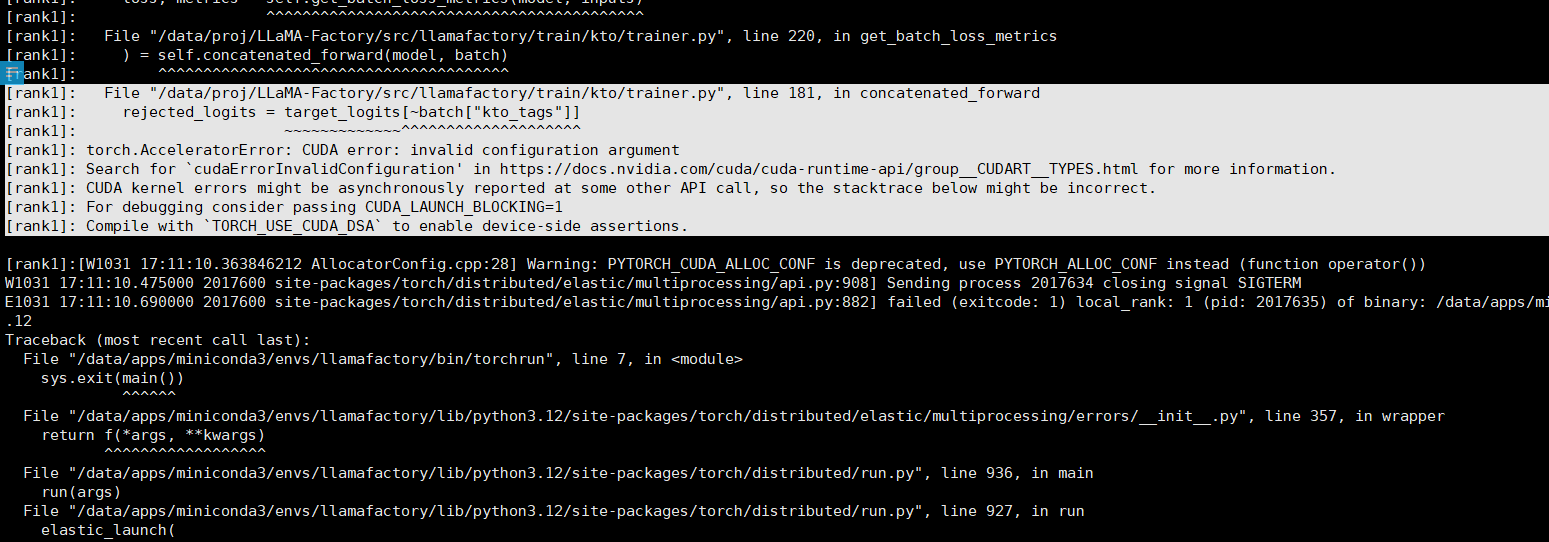
在进行kto训练时,出现了以下报错,考虑是哪里出现了问题呢?求指教
你先试试下面的方法?
1. 立即尝试:减小 batch size
# 在训练配置中减小 per_device_train_batch_size
per_device_train_batch_size: 1 # 或更小的值
gradient_accumulation_steps: 8 # 增加这个来保持有效batch size
2. 启用调试模式定位具体问题
CUDA_LAUNCH_BLOCKING=1 python your_training_script.py
这会给出更详细的错误信息。
3. 检查数据格式
KTO 训练中 kto_tags 可能有问题,检查:
-
batch 中的
kto_tags是否超出了target_logits的索引范围 -
数据集中是否有异常样本
4. 更新环境变量(根据警告提示)
# 替换旧的环境变量
export PYTORCH_ALLOC_CONF=max_split_size_mb:512
# 而不是 PYTORCH_CUDA_ALLOC_CONF
5. 降低序列长度
max_length: 512 # 从更大的值降低
6. 检查 GPU 内存
# 清理 GPU 缓存
nvidia-smi
# 如果内存不足,考虑:
# - 使用梯度检查点
# - 启用 CPU offload
快速修复建议
先尝试这个组合:
CUDA_LAUNCH_BLOCKING=1 \
PYTORCH_ALLOC_CONF=max_split_size_mb:256 \
python your_script.py \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 8 \
--max_length 512
如果问题依然存在,请分享:
-
你的完整训练配置
-
训练数据样例
-
GPU 型号和显存大小
-
使用
CUDA_LAUNCH_BLOCKING=1后的详细错误信息